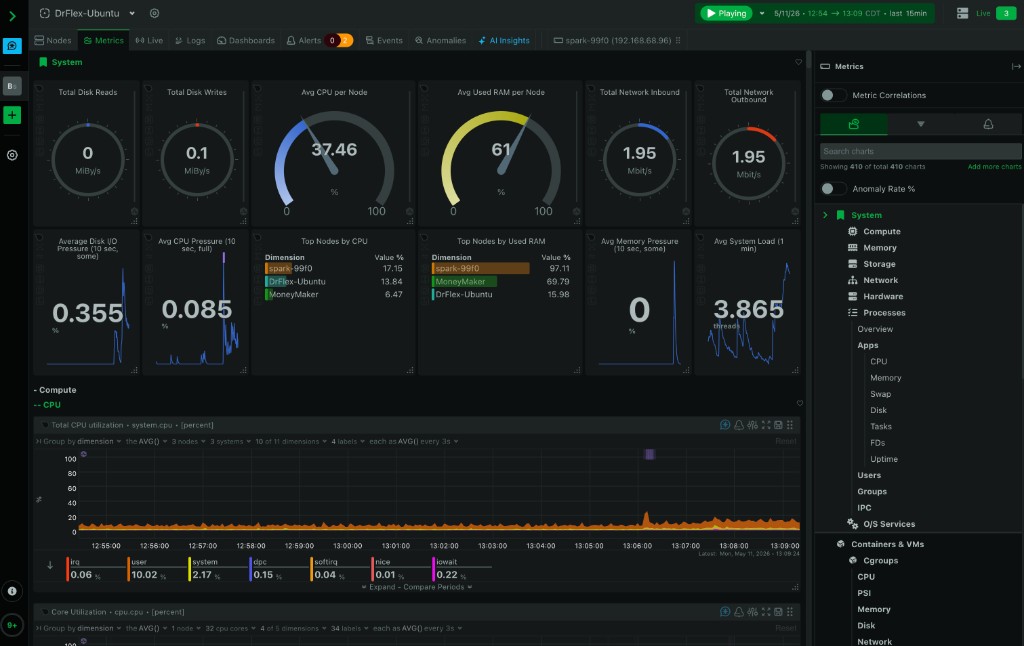
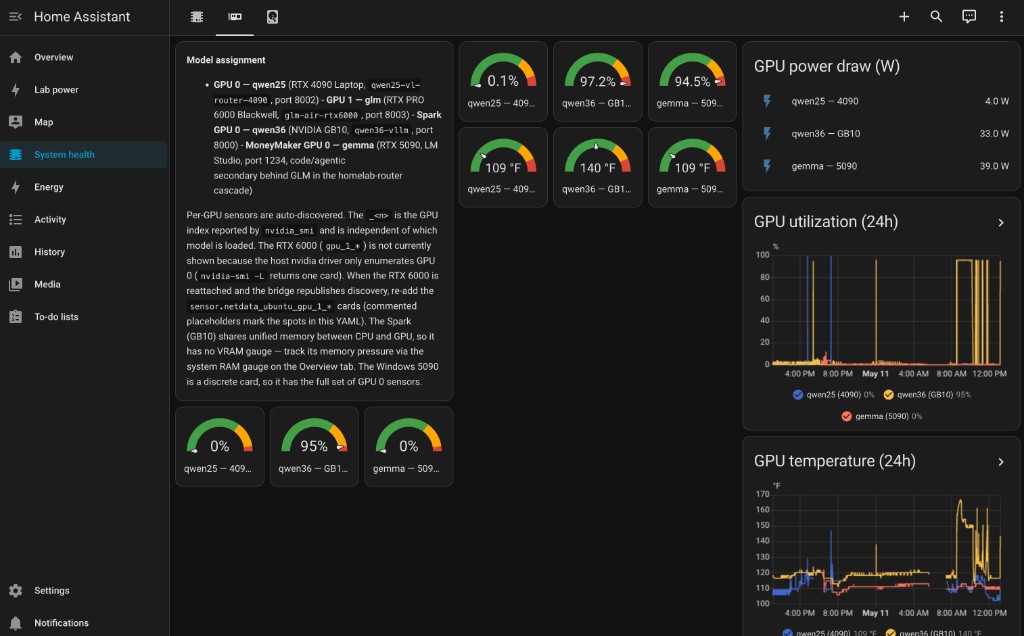
The Eyes
ubuntu-4090
Fast vision, JSON utility, low-latency routing pre-filter.
homelab/visionhomelab/fast
Hardware
GPURTX 4090 Laptop GPU
VRAM16 GB
BusInternal PCIe (workstation)
OSUbuntu
Production model
ModelQwen2.5-VL-7B-Instruct-AWQ
Served asqwen2.5-vl-7b-router-awq
RuntimevLLM (OpenAI-compatible)
What it does
- Vision — every image-bearing request lands here first
- Ring camera snapshots
- Frigate events
- Screenshot understanding
- Fast classifier: the “is this even worth escalating?” pre-filter
- JSON utility: structured outputs for the camera pipeline, notifications, and tagging
Latency it actually hits
p50 target
≤ 1 s
p95 target
≤ 2 s
p50 measured
0.61 s
p95 measured
0.81 s
- · 4 / 4 routing safety cases pass
- · Zero false suppressions
- · Zero invalid JSON
Optimizations
- AWQ INT4 quantization — one-fifth the weights of FP16
- vLLM with continuous batching and prefix caching
- Production context locked to 32K tokens after a latency / KV / VRAM sweep
- Auto-start as a user-level systemd unit — no manual login after reboot
- Approximately 9.5 GB of 16 GB used, leaving headroom for CUDA-graph capture and prefix-cache growth
Hard rules
- Nothing else co-hosts on the 4090 — no coding model, no large-context model
- The slot is single-purpose on purpose
Recovery story
When the eGPU on the sibling machine has a PCIe link-down/up cycle, the entire NVIDIA driver enters a degraded state where nvidia-smi still works but every fresh CUDA init fails. The router detects this, fails traffic over to Spark, and a recover-cuda.sh script reloads the NVIDIA UVM module and brings everything back up automatically. The whole sequence is documented step-by-step in the runbook.
vLLM launch (excerpt)
# qwen2.5-vl-7b-router-awq on ubuntu-4090
vllm serve Qwen/Qwen2.5-VL-7B-Instruct-AWQ \
--served-model-name qwen2.5-vl-7b-router-awq \
--quantization awq_marlin \
--max-model-len 32768 \
--gpu-memory-utilization 0.78 \
--enable-prefix-caching \
--enforce-eager false \
--host 127.0.0.1